es-通过Analyzer进行分词-03
Elasticsearch 通过Analyzer进行分词
Analysis 与 Analyzer
- Analysis - 文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词
- Analysis 是通过Aanlyzer来实现的
- 可使用Elasticsearch内置的分析器/或者按需定制化分析器
- 除了在数据写入时转换词条,匹配Query语句时候也需要用相同的分析器对查询语句进行分析
Analyzer的组成
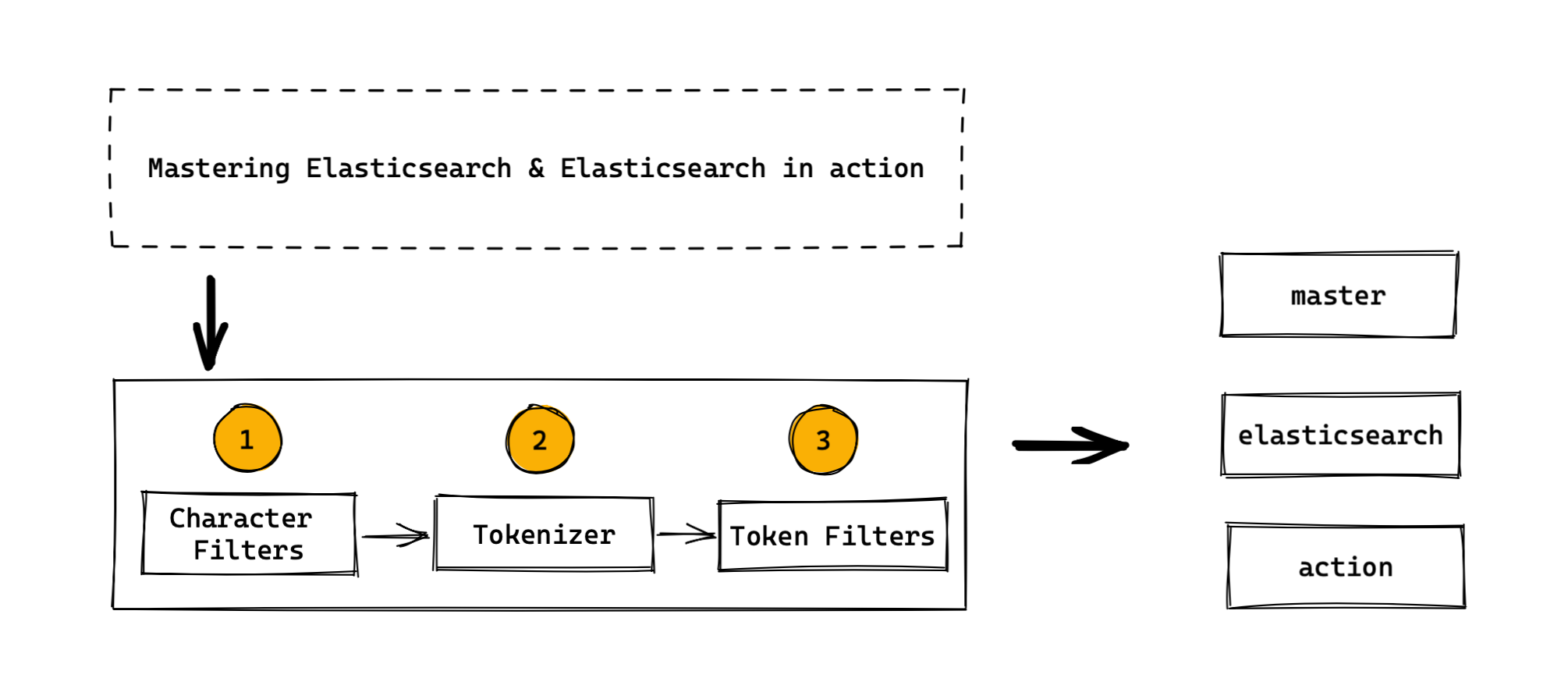
- 分词器是专门处理分词的组件,Analyzer由三部分组成
- Character Filter(针对原始文本处理,例如去除html)
- Tokenizer (按照规则切分为单词)
- Token Filter(将切分的单词进行加工,小写,删除stopwrods,增加同义词)
Elasticsearch 的内置分词器
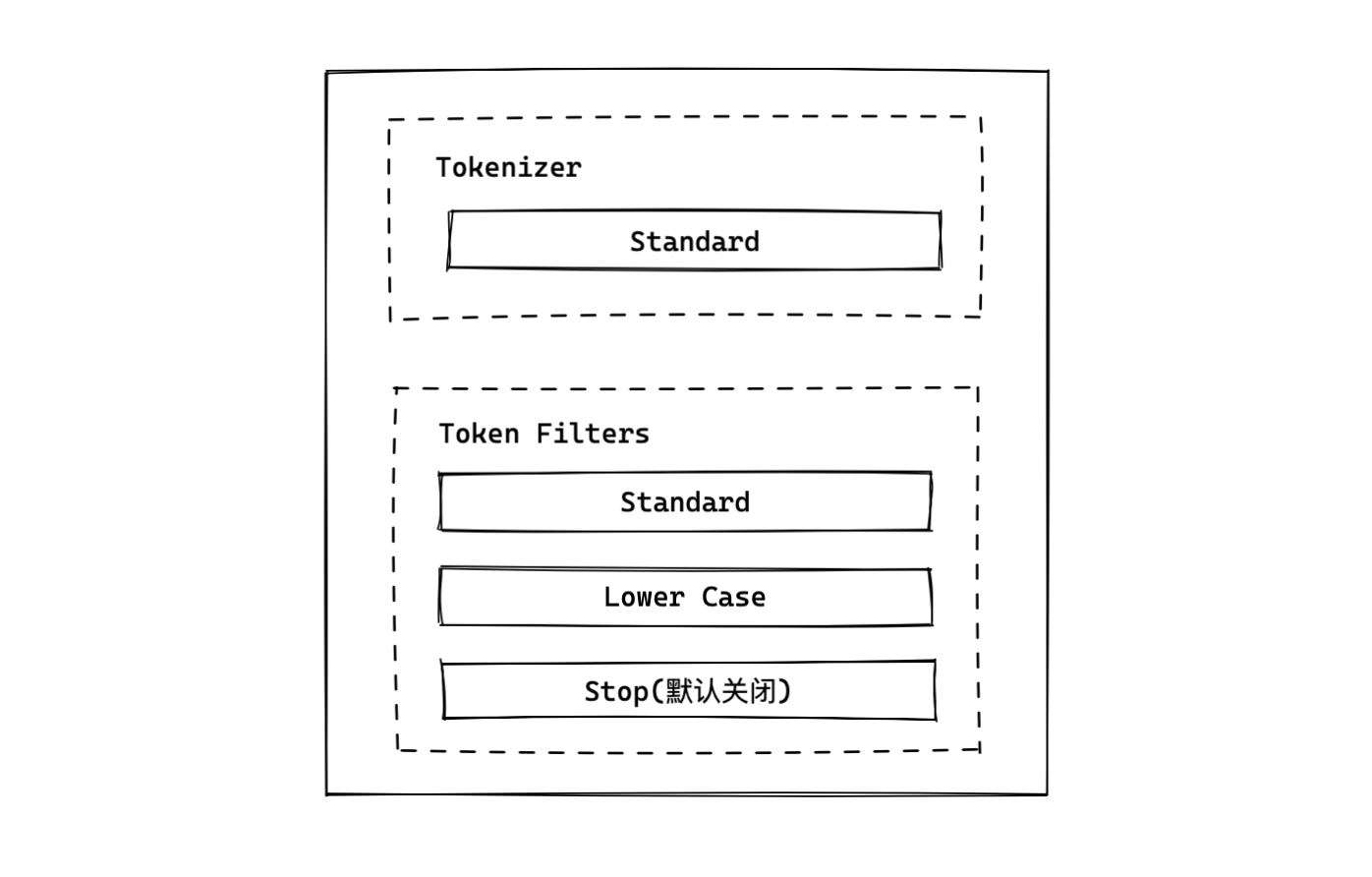
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Pattern Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
使用_analyzer API
直接指定Analyzer进行测试
1
2
3
4
5GET _/_analyze
{
"analyzer": "standard",
"text": "Mastering Elasticsearch, elasticsearch in Action"
}指定索引的字段进行测试
1
2
3
4
5POST books/_analyze
{
"field": "title",
"text": "Mastering Elasticsearch"
}自定义分词进行测试
1
2
3
4
5
6POST /_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "Mastering Elasticsearch"
}
Standard Analyzer
- 默认分词器
- 按词切分
- 小写处理
1 | |
Simple Analyzer
- 按照非字母切分,非字母的都被去除
- 小写处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dags in the summer evening"
}
这里2 被去除了,还有符号‘-’,并且单词都转为小写,
Response:
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dags",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
Whitespace Analyzer
- 按照空格切分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dags in the summer evening"
}
Response:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "Quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown-foxes",
"start_offset" : 16,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dags",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
Stop Analyzer
- 相比Simpler Analyzer 多了stop Filter
- 会把 the,a,is等修饰性词语去除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dags in the summer evening"
}
这里把 2,'-',in,the都去除了
Response:
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dags",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
Keyword Analyzer
- 不分词,直接将输入当一个term输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dags in the summer evening"
}
Response:
{
"tokens" : [
{
"token" : "2 running Quick brown-foxes leap over lazy dags in the summer evening",
"start_offset" : 0,
"end_offset" : 69,
"type" : "word",
"position" : 0
}
]
}
Pattern Analyzer
- 通过正则表达式进行分词
- 默认是\W+,非字符的符号进行分隔
- 转小写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dags in the summer evening"
}
Response:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 7
},
{
"token" : "dags",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 12
}
]
}
Language Analyzer

- es 提供了30多种常见语言的分词器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dags in the summer evening"
}
Response:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "run",
"start_offset" : 2,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "fox",
"start_offset" : 22,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "lazi",
"start_offset" : 38,
"end_offset" : 42,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "dag",
"start_offset" : 43,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "even",
"start_offset" : 62,
"end_offset" : 69,
"type" : "<ALPHANUM>",
"position" : 12
}
]
}
ICU Analyzer
- 需要安装plugin
- Elasticsearch-plugin install analysis-icu
- 提供了Unicode的支持,更好的支持亚洲语言
中文分词
中文分词的难点
- 中文句子切分成一个一个词(不是一个个字)
- 英文中,单词有自然的空格做为分隔
- 一句中文,在不同的上下文,有不同的理解
- 这个苹果,不大好吃/这个苹果,不大,好吃!
- 一些例子
- 他说的确实在理/这事的确定下来
中文分词器,这里安装了IK
1 | |
- 拿standard Analyzer 和 IK Analyzer 做个对比吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
GET _analyze
{
"analyzer": "standard",
"text": "他说的确实在理"
}
被拆分成一个个的字
Response:
{
"tokens" : [
{
"token" : "他",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "说",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "的",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "确",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "实",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "在",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "理",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
GET _analyze
{
"analyzer": "ik_smart",
"text": "他说的确实在理"
}
拆分出单个字和一些中文词语的组合,相比standard analyzer 来说,效果还是比较不错的
Response:
{
"tokens" : [
{
"token" : "他",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "说",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "的确",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "实",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "在理",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
}
]
}
拼音分词器
拼音分词器体验了这个插件,https://github.com/medcl/elasticsearch-analysis-pinyin,
1 | |
推荐用下面这种方式,支持中文和拼音混合搜索,搜索的结果比较贴合需求
1 | |
es-通过Analyzer进行分词-03
http://example.com/2022/11/06/es/es-通过Analyzer进行分词-03/