es-深入理解-01
文章内容摘自极客时间《Elasticsearch核心技术与实战》与《Elasticsearch实战》
深入理解 Elasticsaerch
从两个角度来理解es中数据是如何组织的
- 逻辑设计
- 搜索应用所需要注意的。 用于索引和搜索的基本单位是文档,可以将其认为是关系数据库里的一行数据,索引更像是关系型数据库的一张表。
- 物理设计
- 在后台es是如何处理数据的es将每个索引划分为分片,每份分片可以在集群的不同服务器间迁移。通常,应用程序无须关心这些,因为无论是单台还是多台服务器,应用和es的交互基本保持不变。但是,开始管理集群的时候,就需要留心了。原因是,物理设计的配置方式决定了集群的性能,可扩展性和可用性。
理解逻辑设计: 文档、类型和索引
- 文档
- 文档是索引和搜索数据的最小单位
- 一篇文档同时包含字段和它的取值
- 文档可以是多层次的,一个字段的取值可以是简单的(例如字符串),也可以是包含其他字段和取值
- 拥有灵活的结构,文档不依赖于预先定义的模式,并非所有的文档都需要拥有相同的字段,它们不是受限于同一个模式
- 每个文档都有一个unique id,可指定或自动生成
文档的元数据
1 | |
- 类型
- 在老版本一个索引可设置多个类型,新版本已经去除
下面是摘自官方的说明
在Elasticsearch 6.0.0或更高版本中创建的索引可能只包含单一的映射类型。在5.x中创建具有多种映射类型的索引将继续像Elasticsearch 6.x一样发挥作用。类型将在Elasticsearch 7.0.0的API中不建议使用,并在8.0.0中完全删除。
- 索引
- 索引是文档的容器,是一类文档的集合
- 每个索引都有自己的mapping的定义,用于包含文档的字段名和字段类型
- 每个索引存储在磁盘的同组文件中;索引存储了所有映射类型的字段,还有一些配置
- 每一个索引都有一个refresh_interval的设置,定义了新近索引的文档对于搜索可见的时间间隔,默认是每秒更新一次
- 同一个索引是由一个或多个称为分片的数据块组成
理解物理设计:节点和分片
节点
- 一个节点就是一个es实例,多个es节点组成es集群
分片
- 分片是组成索引的数据块
- 分片是es将数据从一个节点迁移到另一个节点的最小单位
- 主分片
- 用以解决数据水平扩展问题。通过主分片,可以将数据分布到集群的所有节点之上
- 一个分片是一个运行的lucene实例
- 主分片数在创建时指定,后续不需修改,除非reindex
- 副本分片
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
抽象与类比
拿传统的关系型数据库和elasticsearch做一下类比:
| RDBMS | Elasticsearch |
|---|---|
| Table | index(type) |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
索引一篇文章时发生了什么
默认情况下,当索引一篇文章时,首先根据文档ID的散列值选择一个主分片,并将文档发送到该主分片。这份主分片可能位于另一个节点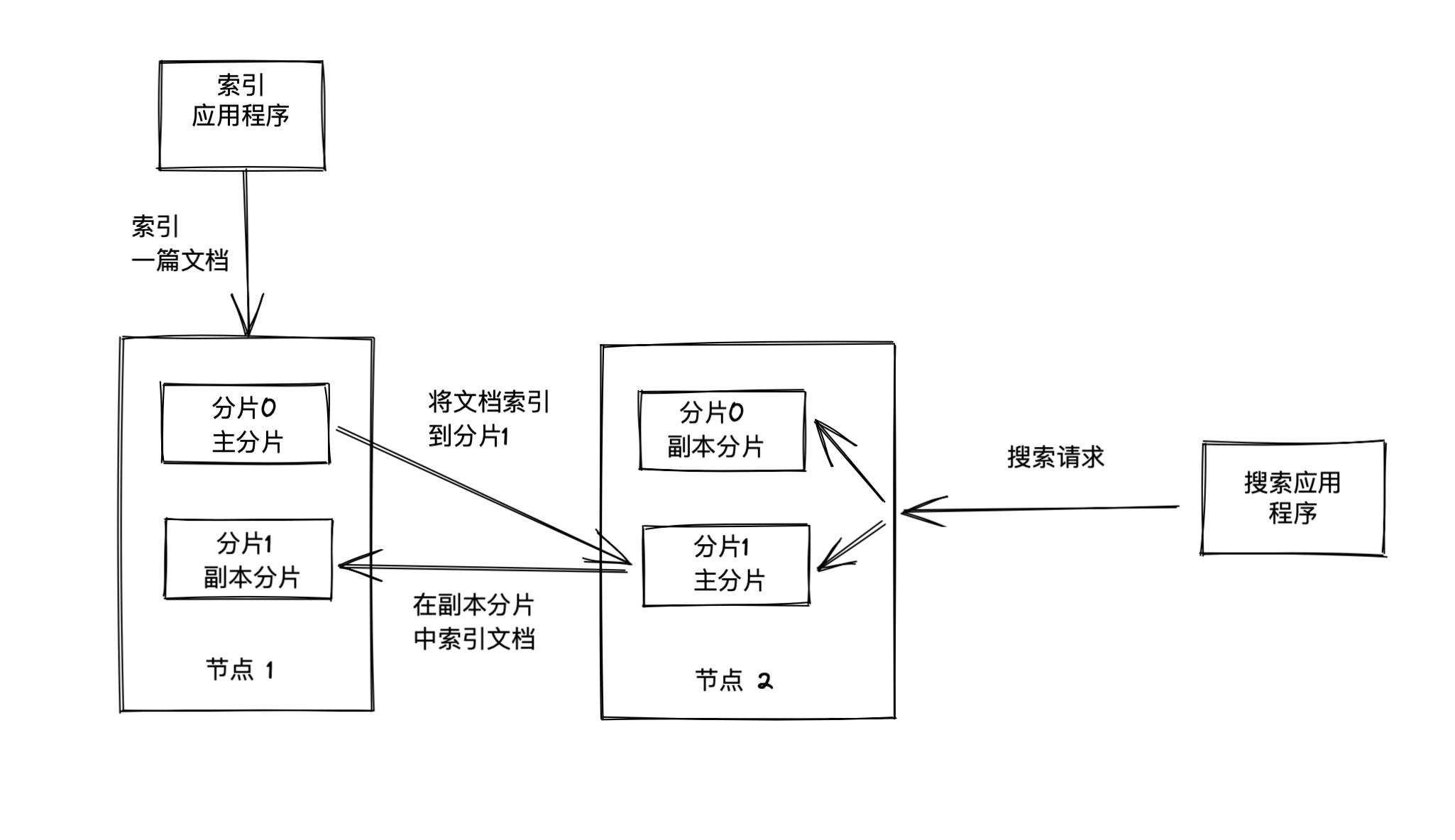
然后文档被发送到该主分片的所有副本分片进行索引。这使得副本分片和主分片之前保持数据的同步。数据同步使得副本分片可以服务于搜索请求,并在原有主分片无法访问时自动升级为主分片。
搜索时发生了什么
当搜索一个索引时,es需要在该索引的完整分片中进行查找,这些分片可以是主分片,也可以是副本分片,原因是对应的主分片和副本分片通常包含一样的文档
什么是倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中的每一个词,都有一个包含他的文档列表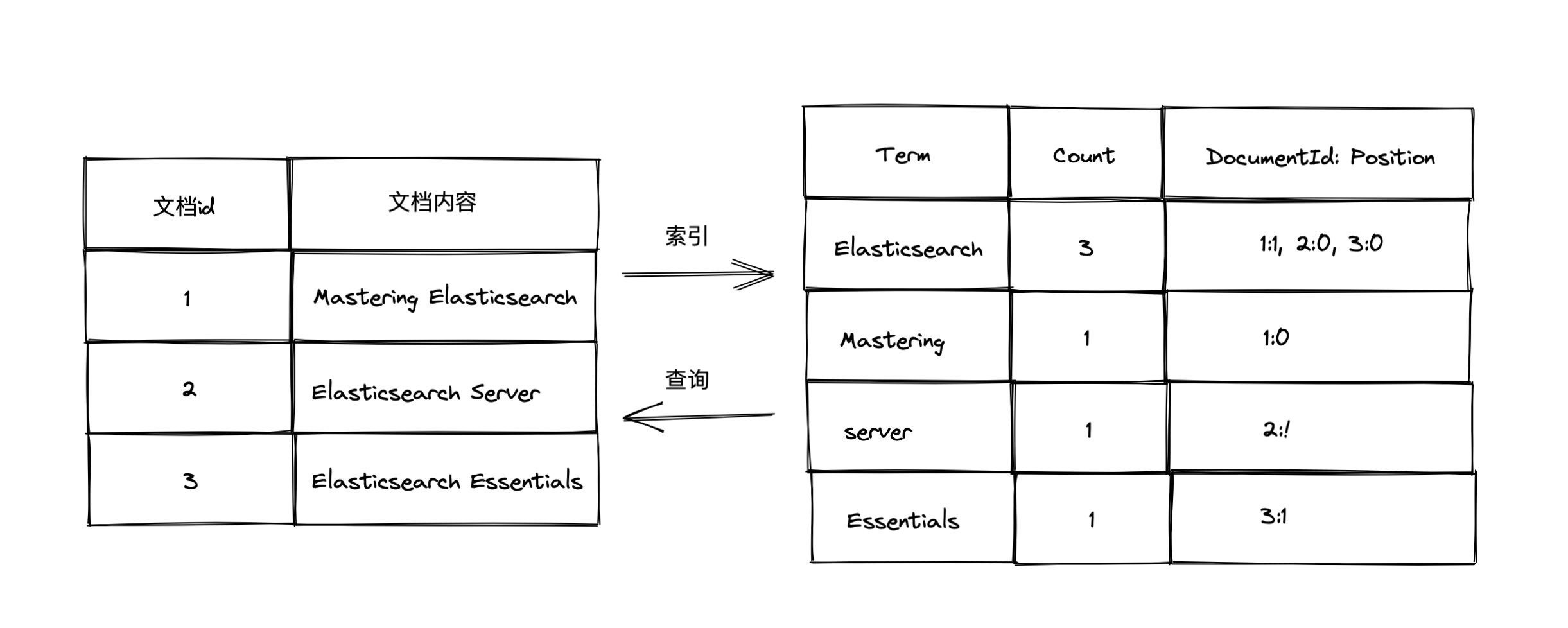
图书和倒排索引的类比
- 图书
- 正排索引 - 目录页
- 倒排索引 - 索引页
- 搜索引擎
- 正排索引 - 文档id到文档内容和单词的关联
- 倒排索引 - 单词到文档id的关系
倒排索引的核心组成
- 倒排索引包含两个部分
- 单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般比较大,可以通过B+树或哈希拉链法实现,已满足高性能的插入与查询
- 倒排列表(Posting List)-记录了单词对应的文档结合,由倒排索引项组成
- 倒排索引项(posting)
- 文档id
- 词频TF -该单词所在文档中出现的次数,用于相关性评分
- 位置(Position)-单词在文档中分词的位置。用于语句搜索(phrase query)
- 偏移(offset) -记录单词的开始结束位置,实现高亮显示
- 倒排索引项(posting)
- 单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系
一个例子 - Elasticsearch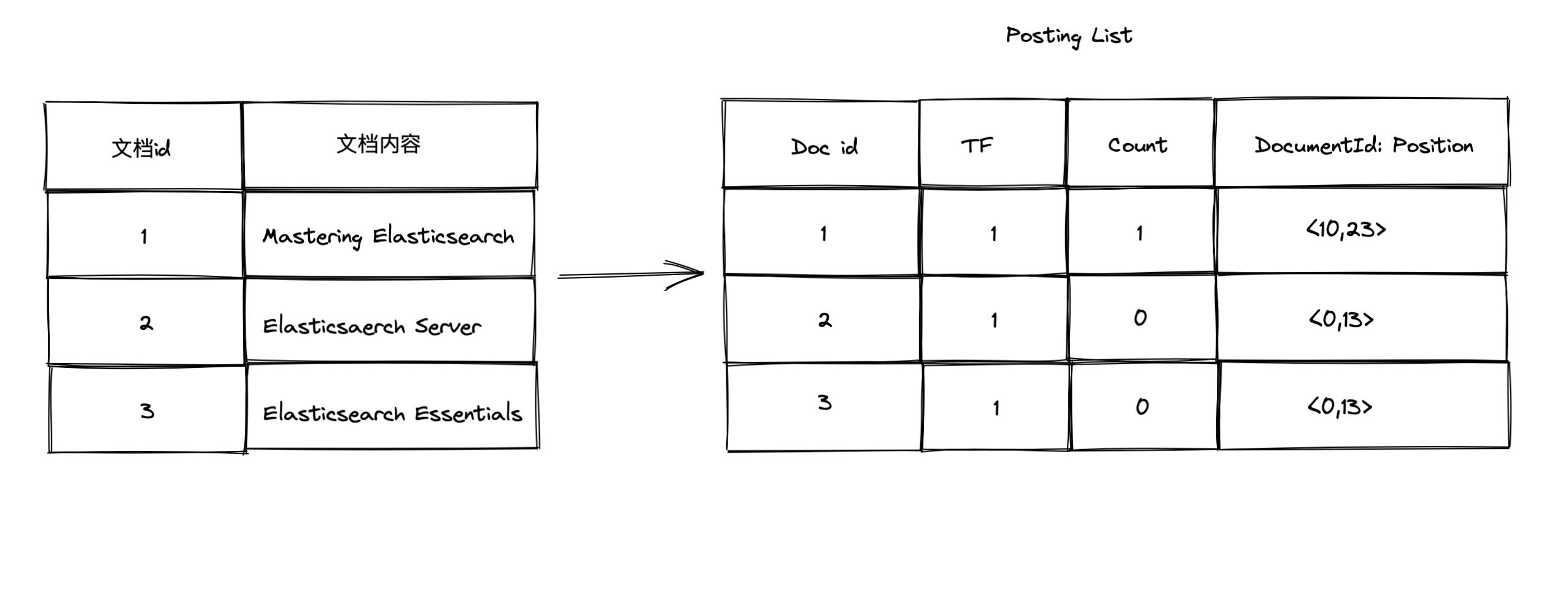
- Elasticsearch 的json文档中的每个字段,都有自己的倒排索引
- 可以指定对某些字段不做索引
- 优点:节省存储空间
- 缺点:字段无法被搜索
es-深入理解-01
http://example.com/2022/11/05/es/es-深入理解-01/